【样本量估算篇】 随机对照试验(两组均数)比较的样本量计算方法
1.临床试验样本量的计算的重要性
临床试验样本量的计算方法是非常重要的,它可以帮助研究人员确定所需的样本大小,以达到统计显著性和足够的统计功效。以下是一些重要性的原因:
- 确保结果的可靠性:样本量的计算可以确保研究结果的可靠性。较大的样本量可以减少随机误差的影响,使得结果更加稳定和可信。
- 控制假阴性和假阳性错误:样本量的计算可以帮助研究人员控制假阴性和假阳性错误的概率。在随机对照试验中,假阴性错误是指研究未能发现真实效应的概率,而假阳性错误是指误判为存在效应的概率。适当的样本大小能够控制这些错误的概率。
- 统计功效的保证:样本量的计算可以帮助研究人员确保试验具有足够的统计功效。统计功效是指试验能够检测到真实效应的能力。通过计算样本量,可以确保试验具有足够的样本数量以检测到目标效应大小。
- 节约研究资源:合适的样本量计算可以帮助研究人员合理规划研究资源。过小的样本量可能导致效应未被检测到,而过大的样本量则可能浪费研究资源。样本量计算可以帮助研究人员在有效利用资源的前提下获得可靠结果。
2.估算公式:
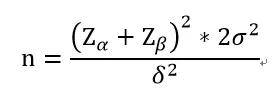
- n代表每组样本量。
- Zα和Zβ需要查表。一般α为0.05,且Z值为双侧,则Z0.05=1.96;β为单侧,把握度(检验效能)为0.9时,Zβ=1.28,把握度(检验效能)为0.8时,Zβ=0.84,一般把握度0.9较多见,但需要更多样本量。
- 𝜎代表标准差。
- 𝛿代表差值,即治疗组与对照组平均值的差值。
3. 案例
西药对照组排尿评分的平均值为7.08±1.36(x̅ ± σ,均数加减标准差)分, 中西医结合治疗组使用药物后预计降低1.2分,二者方差相似。双侧检验,α为0.05,两组样本量比值1:1(即两组病例数相等),把握度(检验效能)1-β=90%,求需要多少样本量?
Zα = Z0.05 = 1.96
Zβ = Z0.9 = 1.28
𝜎 = 1.36
𝛿 = 1.2 (中西医结合治疗组使用药物后预计降低1.2分)
结果:
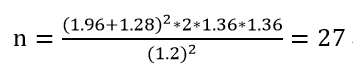
4. 使用PASS 软件计算样本量(本处使用的是PASS 15.0.5)
选择界面:(方差不齐的时候选择旁边的Unequal Variance)

填入数据:

点击 Calculate 获取结果

根据结果显示: 每组需要 28 个志愿者,考虑 20%脱落率,每组需要 35 个志愿者
5.使用Python计算:
在 Python 中,目前没有可以可靠的库直接计算样本量,同样使用一些统计库来辅助计算样本量。其中,常用的库主要是 `scipy` ,它们提供了一些函数和方法来计算Z值。以下是一个示例:
使用代码:
import scipy.stats
α = 0.05 # 双尾
β = 0.9
𝜎 = 1.36
𝛿 = 1.2 # (中西医结合治疗组使用药物后预计降低1.2分)
Zα = scipy.stats.norm.ppf(1 - .05 / 2) # 双尾需要/2
# Zα = 1.959963984540054
Zβ = scipy.stats.norm.ppf(0.9)
# Zβ = 1.2815515655446004
def calculate():
"""
写一个函数计算样本量
"""
return (((Zα + Zβ)**2)*2*(𝜎)**2)/(𝛿**2)
print(f"每组样本量为“{calculate()}")
print(f"考虑20%脱落率,每组样本量为“{calculate()*1.2}")
"""
结果:
每组样本量为“26.992402353389686
考虑20%脱落率,每组样本量为“32.390882824067624
"""
表述方法
公式法:本研究为随机对照试验,治疗组为药物A治疗组,对照组为安慰剂对照组,研究对象的排尿症状评分为观测的结局指标,根据查阅文献以及预实验结果,安慰剂对照组的排尿症状评分均数为7.08±1.36分,预计药物A治疗组的排尿症状可下降1.2分,设双侧α=0.05,把握度为90%。根据样本量计算公式:
计算得到治疗组和对照组各需研究对象27例,考虑失访以及拒访的情况,最终至少需要的治疗组和对照组研究对象各为34例,总计至少纳入68例研究对象。
表述二,PASS软件法:本研究为随机对照试验,治疗组为药物A治疗组,对照组为安慰剂对照组,研究对象的排尿症状评分为观测的结局指标,根据查阅文献以及预实验结果,安慰剂对照组的排尿症状评分均数为7.08±1.36分,预计药物A治疗组的排尿症状可下降1.2分,设双侧α=0.05,把握度为90%。利用PASS 15软件计算得到治疗组的样本量N1=28例,对照组的样本量N2=28例,考虑失访以及拒访的情况20%计算,最终至少需要的治疗组和对照组研究对象各为35例,总计至少纳入70例研究对象。
总结
三种计算方法其实就是两种,Python的计算也是根据公式进行构造,PASS计算可能是由于精度问题,但是这个几乎不影响,目前常见试验类型比较权威的还是推荐PASS,也比较简单易懂。
参考文章:
样本量估算(二):随机对照试验(两组均数)比较的样本量计算方法_研究 (sohu.com)2024-01-5部分内容具有时效性,如有失效,请联系邮箱:heiyingcyh@163.com